Помогите разобраться, почему не выводит данные при компиляции. Задача вставить код Python в Loginom и прописать входные/выходные значения. "Разрешить формировать выходные столбцы из кода" - галочка стоит
Код из Pycharm:
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
iris = load_iris()
data = pd.DataFrame(data=iris.data, columns=iris.feature_names)
data['target'] = iris.target
X = data.drop('target', axis=1)
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Точность модели: {accuracy:.2f}')
Переделала для Loginom:
import pandas as pd
import numpy as np
from builtin_data import InputTable, OutputTable
from builtin_pandas_utils import to_data_frame, prepare_compatible_table, fill_table
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# Проверяем, есть ли входной набор данных
if InputTable:
# Преобразуем входной набор данных в DataFrame
input_frame = to_data_frame(InputTable)
# Проверяем, что все необходимые столбцы есть во входных данных
required_columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'target']
if all(col in input_frame.columns for col in required_columns):
try:
# Разделяем данные на признаки (X) и целевую переменную (y)
X = input_frame[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]
y = input_frame['target']
# Разделяем данные на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Создаём и обучаем модель K-ближайших соседей
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
# Предсказываем значения на тестовых данных
y_pred = model.predict(X_test)
# Оцениваем точность модели
accuracy = accuracy_score(y_test, y_pred)
# Создаём выходной DataFrame с метрикой точности и предсказаниями
output_frame = pd.DataFrame({
"Metric": ["Accuracy"],
"Value": [accuracy]
})
predictions_frame = pd.DataFrame({
"Actual": y_test.values,
"Predicted": y_pred
})
# Формируем структуру выходного набора и заполняем его
if isinstance(OutputTable, builtin_data.ConfigurableOutputTableClass):
prepare_compatible_table(OutputTable, output_frame, with_index=False)
fill_table(OutputTable, output_frame, with_index=False)
except Exception as e:
print(f"Ошибка при обработке данных: {e}")
else:
print("Во входных данных отсутствуют необходимые столбцы.")
else:
print("InputTable отсутствует. Проверьте настройки входного порта.")
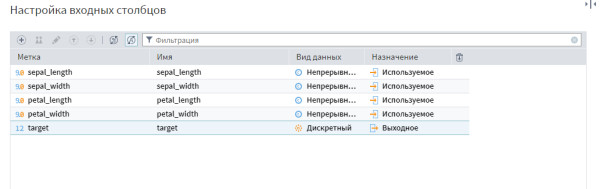
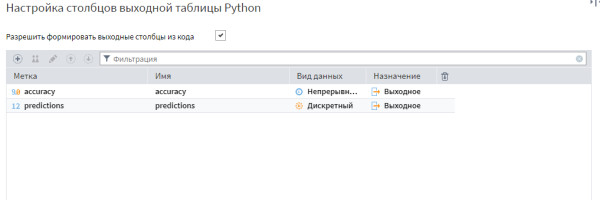
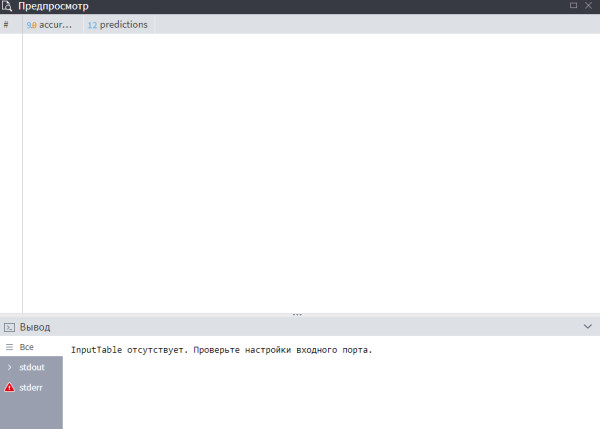
Ещё такой вариант пробовала:
import pandas as pd
import numpy as np
from builtin_data import InputTables, OutputTable
from builtin_pandas_utils import to_data_frame, prepare_compatible_table, fill_table
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# Проверяем, есть ли входной набор данных на втором порту (индекс 1)
if len(InputTables) > 1 and InputTables[1]:
# Преобразуем входной набор данных во второй порт в DataFrame
input_frame = to_data_frame(InputTables[1])
# Проверяем, что все необходимые столбцы есть во входных данных
required_columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'target']
if all(col in input_frame.columns for col in required_columns):
try:
# Разделяем данные на признаки (X) и целевую переменную (y)
X = input_frame[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]
y = input_frame['target']
# Разделяем данные на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Создаём и обучаем модель K-ближайших соседей
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
# Предсказываем значения на тестовых данных
y_pred = model.predict(X_test)
# Оцениваем точность модели
accuracy = accuracy_score(y_test, y_pred)
# Создаём выходной DataFrame с метрикой точности и предсказаниями
output_frame = pd.DataFrame({
"Metric": ["Accuracy"],
"Value": [accuracy]
})
predictions_frame = pd.DataFrame({
"Actual": y_test.values,
"Predicted": y_pred
})
# Формируем структуру выходного набора и заполняем его
if isinstance(OutputTable, builtin_data.ConfigurableOutputTableClass):
prepare_compatible_table(OutputTable, output_frame, with_index=False)
fill_table(OutputTable, output_frame, with_index=False)
except Exception as e:
print(f"Ошибка при обработке данных: {e}")
else:
print("Во входных данных отсутствуют необходимые столбцы.")
else:
print("InputTable отсутствует или данные на втором порту отсутствуют. Проверьте настройки входного порта.")